Friday, 1 November 2019
Talend tMap to Row Number using Variables
Below is a short video which walks you through a different method to derive a row_number, within Talend Open Studio, using the variables within tMap.
https://youtu.be/UbPU7VVu-fU
The notes within the video are below:
20191101 Talend TOS Using tMap to calculate the row number, using the variables
FileInputDelimited > SortRow > tMap > LogRow
select
*
,row_number() over (partition by name order by exam_date) as rn
from name_grades
name,subject,grade,exam_date
andrew,maths,a,2019/01/01
andrew,english,b,2019/01/02
andrew,science,c,2019/01/03
boris,maths,c,2019/01/01
boris,english,a,2019/01/02
boris,science,g,2019/01/03
jeremy,maths,a,2019/01/01
jeremy,english,a,2019/01/02
jeremy,science,a,2019/01/03
donald,maths,u,2019/01/01
donald,english,u,2019/01/02
donald,science,u,2019/01/03
** var expressions **
name = input name
rn = Var.previous_name == null ? 1 : ( Var.name.equals( Var.previous_name ) ? Var.rn + 1 : 1 )
previous_name = input name
Wednesday, 16 October 2019
Talend Row_Number functionality using tMap and Sequence
This post quickly details the steps involved in mimicking the tsql’s row_number() over (partition by…) windows function, all within Talend’s TOS (Talend Open Studio).
We want to add a new column, which is the equivalent to the tsql
row_number() over (partition by name order by 1) as rownumber
tFixedFlowInput > tMap > tLogRow
“>” is a “Row > Main” flow.
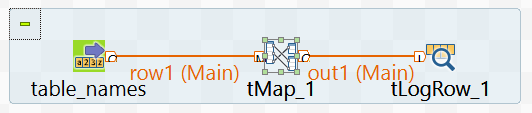 (I’ve renamed my tFixedFlowInput component to “table_names”)
(I’ve renamed my tFixedFlowInput component to “table_names”)
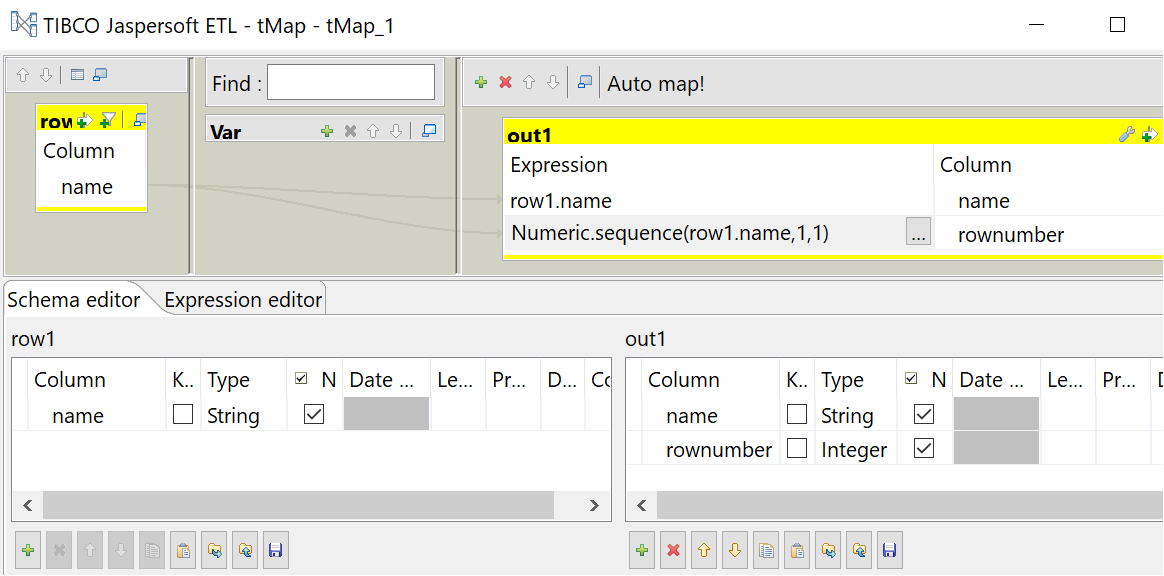
Note that I use an expression to populate the “rownumber” column.
Numeric.sequence(row1.name,1,1)
This expression can be explained as:
Scenario
The starting point is the table of names below.| name |
| andrew |
| andrew |
| andrew |
| berty |
| berty |
| emily |
| emily |
| emily |
| edward |
| edward |
| edward |
| edward |
| hugo |
We want to add a new column, which is the equivalent to the tsql
row_number() over (partition by name order by 1) as rownumber
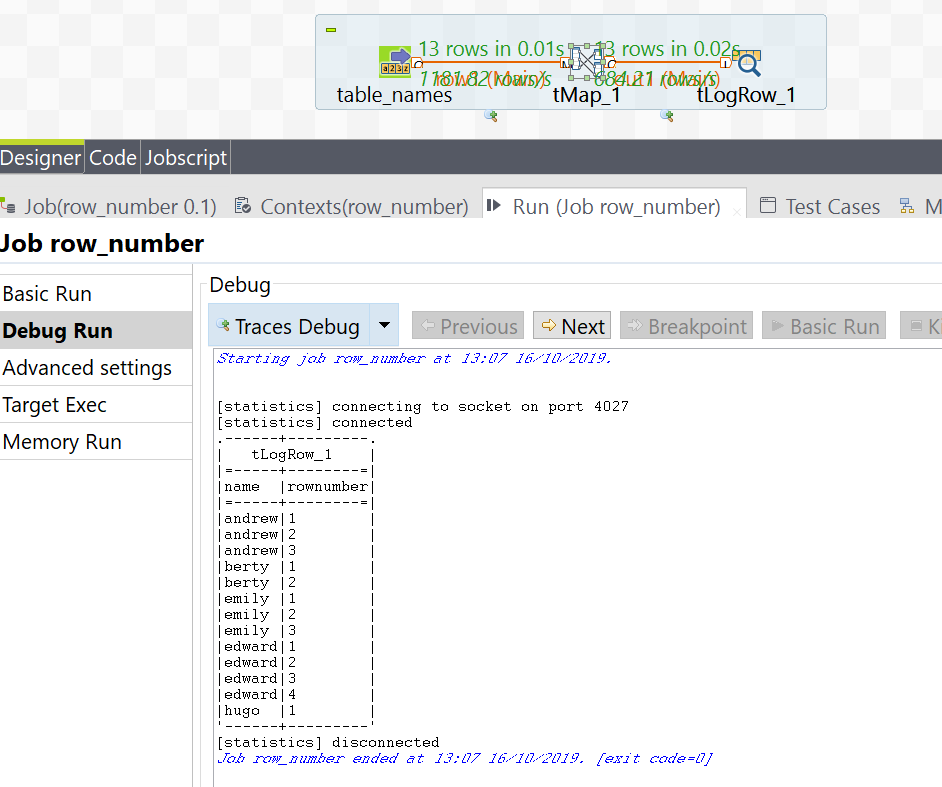
| name | rownumber |
| andrew | 1 |
| andrew | 2 |
| andrew | 3 |
| berty | 1 |
| berty | 2 |
| emily | 1 |
| emily | 2 |
| emily | 3 |
| edward | 1 |
| edward | 2 |
| edward | 3 |
| edward | 4 |
| hugo | 1 |
Talend TOS
In Talend Open Studio, create a job with the following components:tFixedFlowInput > tMap > tLogRow
“>” is a “Row > Main” flow.
tFixedFlowInput
I configure this component to- schema is just 1 column “name” of "String” datatype

- use the inline content below
andrew
andrew
andrew
berty
berty
emily
emily
emily
edward
edward
edward
edward
hugo
tMap
In this component I declare an output “out1” with columns- name, with String type
- rownumber, with Integer type
Note that I use an expression to populate the “rownumber” column.
Numeric.sequence(row1.name,1,1)
This expression can be explained as:
- Numeric.sequence : this defines a integer sequence
- row1.name : this is the column that is “partition by” and “order by” when compared to the tsql windows function
- 1 : the first “1” is the starting point for the sequence
- 1 : the second “1” is the sequence increment
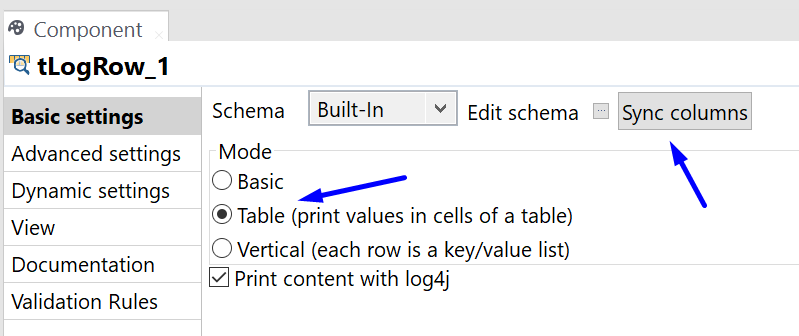
tLogRow
Finally, the results are returned back to the execution console for review, using the tLogRow component.The Results
Below is a screenshot of the final execution results.Tuesday, 1 October 2019
Aginity Pro and Aginity Team
Post seminar questions and answers:
Links:
- https://www.aginity.com/products/aginity-pro/
- https://www.aginity.com/blog/
- https://www.aginity.com/news/
- https://www.aginity.com/products/aginity-workbench/
Hi Fai,
This is George, one of Aginity’s product managers. I wanted to thank you once again for joining our webinar on September 10th.
You had a number of good questions during the webinar that I wanted to make sure I addressed, in case we hadn’t previously.
First, you asked about the ability to look at the distribution of a table in Redshift. I wanted to let you know that we’ve heard that feedback before and our goal is to add that capability soon. We recognize how useful it is.
You also asked for the ability to get a quick look at table sizes for Redshift. This is another request we’ve heard, and we’ve added it to our queue for consideration.
You had a suggestion about raising an alert or warning about a DELETE issued without a WHERE clause – this is an interesting idea, and one that I can raise with our broader team. I can see this being a useful option for individuals; we’d want to make sure we constructed it correctly so that we don’t interrupt workflows among individuals who intend to do this sort of thing regularly.
You asked about limited the return of a query that could result in thousands or millions of rows. We do have in Aginity Pro a configurable limit and we will return no more than that number of rows for any given query.
You asked about where the result data are stored after a query result, in local memory or in a local temporary file. We use memory inside the application to store the results and release the memory when results are no longer needed. Depending on how memory is configured for any user’s particular system, this may include “virtual memory” that is stored on disk.
You asked about the contents of the log in Aginity Pro/Team as well as the Query History. We have an extensive log in Aginity Pro and Team, but we separately maintain a query history for each individual user that is accessible using the Discovery Assistant.
Finally, you asked about the display of JSON results. We don’t currently automatically format such JSON to be “pretty-printable”, but that’s a suggestion I can bring to our team and evaluate.
Thanks Fai for being such an active member of the Aginity community!
Best
George L’Heureux
George C. L'Heureux, Jr. » Enterprise Product Manager & Director of Solution Architecture » Aginity
twitter @aginity
Friday, 27 September 2019
Excel hidden sheets, unhide all macro button
This short guide contains the instructions on how to create a menu ribbon
button that unhides all hidden sheets.
The button actually triggers a macro, details of which are below.
The button actually triggers a macro, details of which are below.
- Open a new excel workbook
- Start to record a new macro
- Give the macro a name “unhide_all_sheets”, and store the macro in “Personal
Macro Workbook”

- Type a short string into any cell, then stop the macro recording

- Now, lets edit the macro.
Via the keyboard, press “ALT + F11”. - In the “Microsoft Visual Basic for Applications” window,
in the “Project” pane, find and open the newly created module in the “PERSONAL.XLSB” VBAProject.
- Replace the code with the code below Sub unhide_all_sheets()
- Close the window, and confirm that the macro is available by clicking on the
menu options
View > Macros
- To add this macro as a button in the excel ribbon, click on the “Customize
Quick Access Toolbar” button at the top of excel, and then click on the “More
Commands” option

- Add the macro to the toolbar

- In the “Choose commands from” change the dropdown to show “Macros”
- Click on the “PERSONAL.XLSB!unhide_all_sheets” macro
- Click on “Add” to add this macro onto the right-side window
- Optionally click on the “Modify” button to change the icon for the macro,
and then click OK to save changes

- Test the button by creating and hiding new excel sheets in the same workbook to show that the hidden sheets are unhidden.
For Each sh In Worksheets: sh.Visible = True: Next sh
End Sub
Wednesday, 18 September 2019
Youtube Keyboard Shortcuts
Youtube keyboard shortcuts are shown in the table below.
These are copied from the page:
https://sites.google.com/a/umich.edu/u-m-google-170816/accessibility/google-keyboard-shortcuts---youtube
These are copied from the page:
https://sites.google.com/a/umich.edu/u-m-google-170816/accessibility/google-keyboard-shortcuts---youtube
| Action | Shortcut |
|---|---|
| Toggle play/pause the video |
k or Spacebar |
| Go back 5 seconds |
Left arrow |
| Go back 10 seconds |
j |
| Go forward 5 seconds |
Right arrow |
| Go forward 10 seconds |
l |
| Skip to a particular section of the video (e.g., 5 goes to the video midpoint) |
Numbers 1-9 (not the keypad numbers) |
| Restart video |
0 (not the keypad number) |
| Go to Full Screen mode | f |
| Exit Full Screen mode |
Escape |
| Go to beginning of video |
Home |
| Go to end of video |
End |
| Increase volume 5% |
Up arrow |
| Decrease volume 5% |
Down arrow |
| Increase speed |
Shift+> (may not work in all browsers) or Shift+. (period) |
| Decrease speed |
Shift+< (may not work in all browsers) or Shift+, (comma) |
| Move forward 1 frame when video is paused | . (period) |
| Move backward 1 frame when video is paused | , (comma) |
| Mute/unmute video | m |
| Turn captions on/off | c |
| Cycle through options for caption background color | b |
| Move to the previous video in a playlist | Shift+p |
| Move to the next video in a playlist | Shift+n |
How to record VOICEOVER AUDIO for gameplay notes
Notes of FXhome's "How to record VOICEOVER AUDIO for gameplay"
https://www.youtube.com/watch?v=iMS4xzd_-yY
Use Audacity to optimise the audio
(download from https://www.audacityteam.org/)
1) highlight section of background noise > effects > noise reduction > get noise profile
2) highlight everything (ctrl+a) > effects > noise reduction > ok
3) ctrl+a > effects > compressor
threshold = how much of the audio will be compressed
ratio = how much compression will be applied
4) ctrl+a > effect > limiter > -0.1 dB
5) file > export > export as wave
6) use the exported WAV file in HITFILM Express, or other video editor
https://www.youtube.com/watch?v=iMS4xzd_-yY
Use Audacity to optimise the audio
(download from https://www.audacityteam.org/)
1) highlight section of background noise > effects > noise reduction > get noise profile
2) highlight everything (ctrl+a) > effects > noise reduction > ok
3) ctrl+a > effects > compressor
threshold = how much of the audio will be compressed
ratio = how much compression will be applied
4) ctrl+a > effect > limiter > -0.1 dB
5) file > export > export as wave
6) use the exported WAV file in HITFILM Express, or other video editor
Wednesday, 11 September 2019
Talend Component crib sheet
Here’s a handy reference table for the common Talend components.
Use this document as a reference to understand what types of flows act as input and output.| Input | Component | Component Description | Output |
| · Row.Iterate · Trigger |  | tPostgressqlConnection | · Trigger |
| · Row.Main | tMap map input to output columns derive columns perform transformations | · Row.Main | |
| · Row.Main |  | tLogRow used as data viewer and debugging print input data in the Run window | · Row.Main · Trigger |
| · Row.Main |  | tPostgresqlOutput used to insert input data into the database | · Row.Main · Trigger |
| · Row.Iterate · Trigger |  | tFileList This outputs an iterative list of files read from a location. The input can be from a trigger or from another row.iterate. | · Row.Main · Trigger |
| · Row.Iterate · Trigger |  | tFileInputDelimited reads data into the job so that the field attributes / schema can be further transformed | · Row.Main · Row.Iterate · Trigger |
| · Row.Iterate · Trigger |  | tFileInputJSON reads data from a location. presents this data / schema to the job for further transformations. | · Row.Main · Row.Iterate · Trigger |
| · Row.Main |  | tFileOutputDelimited used to write data to a file in a specified location | · Row.Main · Trigger |
| · Row.Iterate · Row.Main · Trigger |  | tJava used to run arbitrary java code, to help with bespoke transformations. can be used to set values to context variables, or to print messages back to the run window to help debugging the job. | · Row.Main · Row.Iterate · Trigger |
| · Row.Iterate · Row.Main |  | tExtractJSONField used to split key:value pair data from a field / string | · Row.Main · Row.Iterate · Trigger |
| · Row.Iterate |  | tIterateToFlow converts row.iterate to a row.main | · Row.Main · Trigger |
| · Row.Main |  | tFlowToIterate converts row.main to a row.iterate | · Row.Iterate · Trigger |
| · Row.Iterate · Trigger |  | tS3Connection creates a connection to AWS S3 | · Trigger |
| · Row.Iterate · Trigger |  | tS3List used to list the objects in S3 bucket outputs this list for iteration | · Row.Iterate · Trigger |
| · Row.Iterate · Trigger |  | tS3Get used to download the objects from s3 to a location | · Trigger |
| · Row.Iterate · Trigger |  | tHashOutput used to load row.main data flow into local cache | · Row.Iterate · Row.Main · Trigger |
| · Row.Main |  | tHashInput used to retrieve data from local cache for further transformation within the job | · Row.Main · Trigger |
AWS Redshift notes
SQL Clients
- Aginity for Redshift
- https://www.aginity.com/products/aginity-workbench/
(download for PC at the bottom) - https://www.aginity.com/main/thanks-aginity-workbench/?product=amazon-64
- Final release notes (for version 4.9.3.2783)
https://support.aginity.com/hc/en-us/articles/360016160533-Aginity-Workbench-for-Redshift-Downloads - Aginity Pro
Workbench has been superseded by Aginity Pro (which is free for personal use)
Script resources
- Github awslabs redshift utilities
https://github.com/awslabs/amazon-redshift-utils
Wednesday, 28 August 2019
Talend TOS TMap Join configuration – Match Model
https://www.talendbyexample.com/talend-tmap-component-joins.html

This short article contains text-snippets from the link above.
It explains the important considerations when joining data together using tMap component, in Talend Open Studio.
Lookup Model
Normally, you would choose to load your look-up input only once. This is the default Lookup Model of Load Once.
If you have a use-case where you need to reload the look-up input for each of your primary rows, then you have the option of Reload at each row or Reload at each row (cache). Depending on the size of your inputs, either of these latter two options are likely to severely impact the throughput of your Job.
Match Model
The default Match Model is the curiously named Unique match.
If your primary row matches multiple rows in your look-up input, then only the last matching row will be output.
The remaining options are First match, where only the first matching row will be output, and All matches where all matching rows will be output.
Join Model
The default Join Model is Left Outer Join, that is, if no matching row appears in the look-up input, rows from the primary input will still be output.
If you need to perform an Antijoin, then select this option and exclude rows later, by outputting a key value from your look-up input and subsequently excluding rows where this value is null.
The second option available is Inner Join. In this case, only rows where a successful match has been made against the look-up, will be output.
Store temp Data
If you are processing large datasets, you may find it helpful to set this option to true, to conserve memory. When set to true, you will also need to set Temp data directory path; which may be found on the Advanced settings component tab of tMap. Note that this is likely to have a negative impact on the overall throughput of your Job.
Tuesday, 6 August 2019
How To – Talend TAC Update License Token
How To – Talend TAC Update License Token
This guide details how to get a new license token for TAC.
When a token is about to expire, the notification shown below is visible at the top of TAC.

To renew the token, follow the steps below.
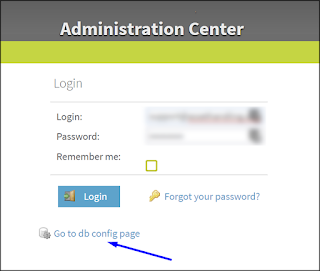
1. On the initial TAC login screen, click on the Go to db config page link below the login button.
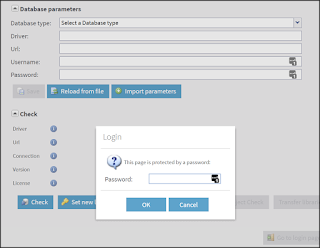
2. Enter the main user or administration password for TAC when prompted.
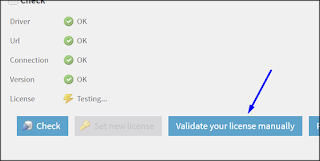
3. Next click on Validate your license manually to manually force a new verification.
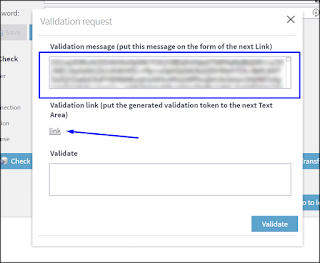
4. A popup-window will appear.
Copy the long string/message in the top box of the popup-window.
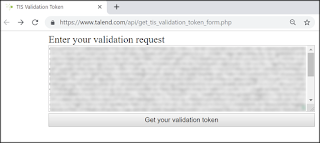
Then click on the link which will open a new browser tab to https://www.talend.com/api/get_tis_validation_token_form.php
5. In this new browser tab, paste the long string/message into the form, and click on the Get your validation token button.
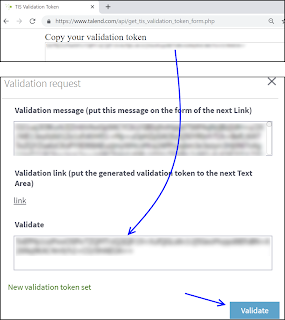
6. Copy the new validation token, and paste this into the bottom box of the previous popup-window mentioned in step (4).
Now click the Validate button.
If successful, then a message in green should state New validation token set.
7. The various configuration checks should all be green-ticks, in particular, the license check.
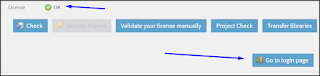
Now click on the Go to login page to return back to the initial TAC login screen and login as normal.
The notification License token will expire should not be present anymore.
If it is, give the server 5 minutes, and log back in again.
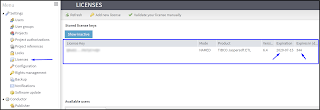
8. As a final check, the license expiry date can be confirmed via the Licenses menu.
This guide details how to get a new license token for TAC.
When a token is about to expire, the notification shown below is visible at the top of TAC.

To renew the token, follow the steps below.

2. Enter the main user or administration password for TAC when prompted.

3. Next click on Validate your license manually to manually force a new verification.

4. A popup-window will appear.
Copy the long string/message in the top box of the popup-window.
Then click on the link which will open a new browser tab to https://www.talend.com/api/get_tis_validation_token_form.php

5. In this new browser tab, paste the long string/message into the form, and click on the Get your validation token button.

6. Copy the new validation token, and paste this into the bottom box of the previous popup-window mentioned in step (4).
Now click the Validate button.
If successful, then a message in green should state New validation token set.

7. The various configuration checks should all be green-ticks, in particular, the license check.

Now click on the Go to login page to return back to the initial TAC login screen and login as normal.
The notification License token will expire should not be present anymore.
If it is, give the server 5 minutes, and log back in again.
8. As a final check, the license expiry date can be confirmed via the Licenses menu.

Thursday, 4 July 2019
Table Tennis Links
A reference page for Table Tennis links.
|
Bats, balls, t-shirts,
|
Videos
|

Friday, 7 June 2019
Postgres Update and Delete statements involving a join
The high-level pg-sql commands below show the syntax for updating or deleting from a postgres table.
--DELETE |
The SQL SERVER equivalent is:
--SQL SERVER update tbl_target delete tbl_target |
Below – the setup scripts for the tables (works for both postgres and sql server)
create table tbl_target (id int, sales int, status varchar(10)); create table tbl_source (id int, sales int, status varchar(10)); select * from tbl_target; |
Monday, 29 April 2019
AWS Secrets Manager python script
"Introduction to AWS Secrets Manager"
https://www.aws.training/learningobject/video?id=19441
The link above is to a 15 minute introductory video that covers the "AWS Secrets Manager" service.
The summary from this training and certification page is:
"In this course, we offer a brief overview of AWS Secrets Manager, highlighting the integration with Amazon Relational Database Service. The video discusses how this service can help manage secrets like OAuth tokens and application API keys, and concludes with a demonstration of how AWS Secrets Manager can generate and automatically rotate your secrets and passwords."
A similar python script that Bridgid used in her training and certification video is:
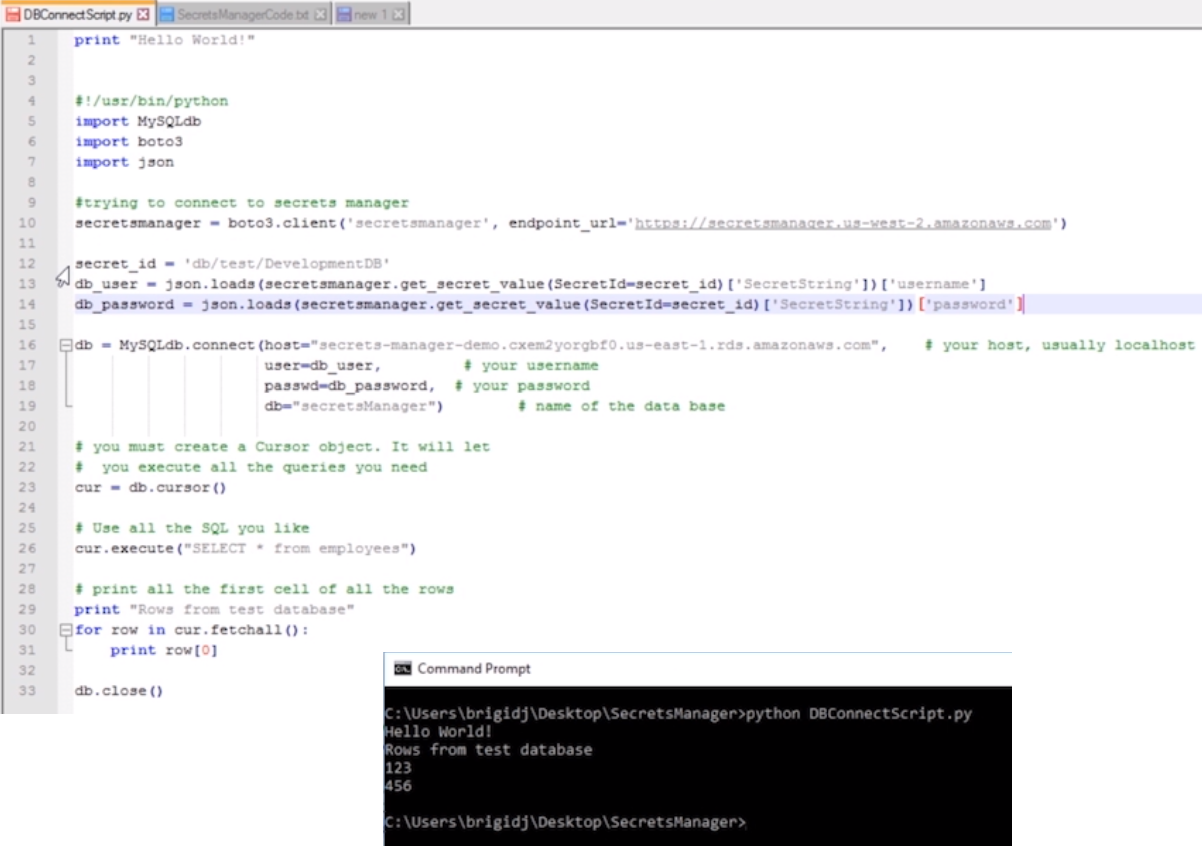
There’s many youtube video’s covering AWS Secrets Manager:
https://www.youtube.com/user/AmazonWebServices/search?query=secrets+manager
https://www.aws.training/learningobject/video?id=19441
The link above is to a 15 minute introductory video that covers the "AWS Secrets Manager" service.
The summary from this training and certification page is:
"In this course, we offer a brief overview of AWS Secrets Manager, highlighting the integration with Amazon Relational Database Service. The video discusses how this service can help manage secrets like OAuth tokens and application API keys, and concludes with a demonstration of how AWS Secrets Manager can generate and automatically rotate your secrets and passwords."
A similar python script that Bridgid used in her training and certification video is:
| print "secrets manager test" #!/usr/bin/python import MySQLdb import boto3 import json #trying to connect to secrets manager secretmanager = boto3.client('secretsmanager', endpoint_url='https://secretmanager.us-west-2.amazonaws.com')/ secret_id = 'db/test/DevelopmentDB' #this is the secret name within aws-SecretManager db_user = json.loads(secretmanager.get_secret_value(SecretId=secret_id)['SecretString'])['username'] db_password = json.loads(secretmanager.get_secret_value(SecretId=secret_id)['SecretString'])['password'] db = MySQLdb.connect(host='secrets-manager--demo.abc123.us-east-1.rds.amazonaws.com', #db endpoint user=db_user, #db username passwd=db_password, #db username password db="secretManager") #db name # you must create a cursor object, it will let you execute all the queries needed cur = db.cursor() cur.execute("select * from employee") # print all the first cell of all the rows print "Rows from the test database" for row in cur.fetchall(): print row[0] # index 0 equates to the first field in the record db.close() |
There’s many youtube video’s covering AWS Secrets Manager:
https://www.youtube.com/user/AmazonWebServices/search?query=secrets+manager
Thursday, 4 April 2019
Talend Admin Center TAC login
Below is the location of the configuration.properties file.
Viewing this file is very handy when locked out of the TAC gui.
The default login for TAC (after a fresh install) is
username: security@company.com
password: admin
To confirm what the default login is, it’s best to refer to the configuration.properties file on the TAC server, as detailed below.
On a local vbox installation, the Talend installation was in the local home directory.
Via a terminal session, the commands to navigate to this directory, and view the file is:
(your installation may be in a different directory, but the path should be similar.
Talend may be a different value dependant on your installation
tac may be a different value dependant on your installation)
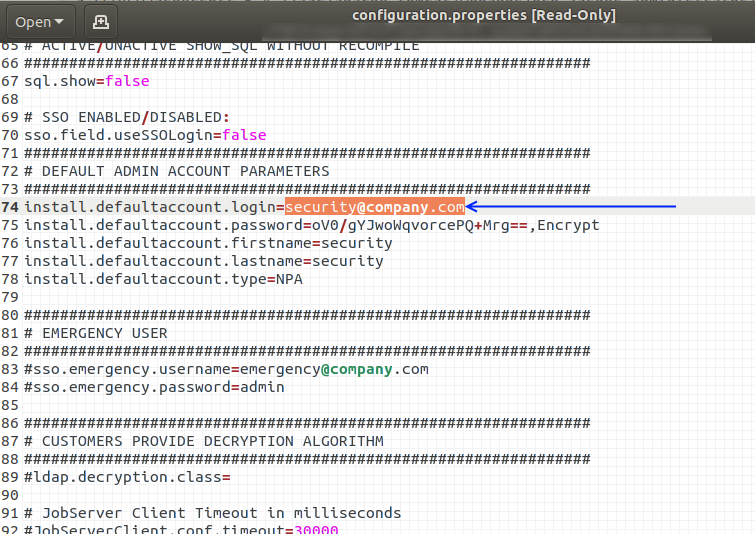
Viewing this file is very handy when locked out of the TAC gui.
The default login for TAC (after a fresh install) is
username: security@company.com
password: admin
To confirm what the default login is, it’s best to refer to the configuration.properties file on the TAC server, as detailed below.
On a local vbox installation, the Talend installation was in the local home directory.
Via a terminal session, the commands to navigate to this directory, and view the file is:
(your installation may be in a different directory, but the path should be similar.
Talend may be a different value dependant on your installation
tac may be a different value dependant on your installation)
| cd ~/Talend/tac/apache-tomcat/webapps/tac/WEB-INF/classes vi configuration.properties |
Wednesday, 3 April 2019
REST API–A to Z
This article contains a summary of notes related to what REST API’s are.
(Care of https://www.smashingmagazine.com/2018/01/understanding-using-rest-api/)
REST API : REpresentational State Transfer Application Programming Interface.
A request to a URL which is the REST API endpoint results in a response containing data which is called the resource.
Anatomy
- The endpoint (or route)
- this is the url, which is made up of a root-endpoint, and path and finally the query
- for example “http://faihofu.blogspot.com/search/label/aws”
”www.faihofu.blogspot.com” is the root-endpoint
”/search/label/aws” is the path - another example “https://www.google.co.uk/search?q=faihofu”
”www.google.co.uk” is the root-endpoint
”/search” is the path
”q=faihofu” is the query - The method
- the headers
- The data (or body or message)
1 Endpoints
When referring to API documentation, the path me be stated as
“/search/label/:labelvalue”
Any colons within the path denote a variable, which need to be replaced when hitting the endpoint.
2 Method
These are the types of API requests:
- Get
- This is the default method to request / read from the endpoint / server
- Post
- This creates a new resource / data on the endpoint server
- Put
- This updates the resource / data on the endpoint server
- Patch
- see PUT
- Delete
- This deletes resource / data on the endpoint server
These methods are used to perform one of the actions (CRUD):
- Create
- Read
- Update
- Delete
3 Headers
“Headers are used to provide information to both the client and server.
You can find a list of valid headers on MDN’s HTTP Headers Reference.”
HTTP Headers are property-value pairs that are separated by a colon.
The example below shows a header that tells the server to expect JSON content.
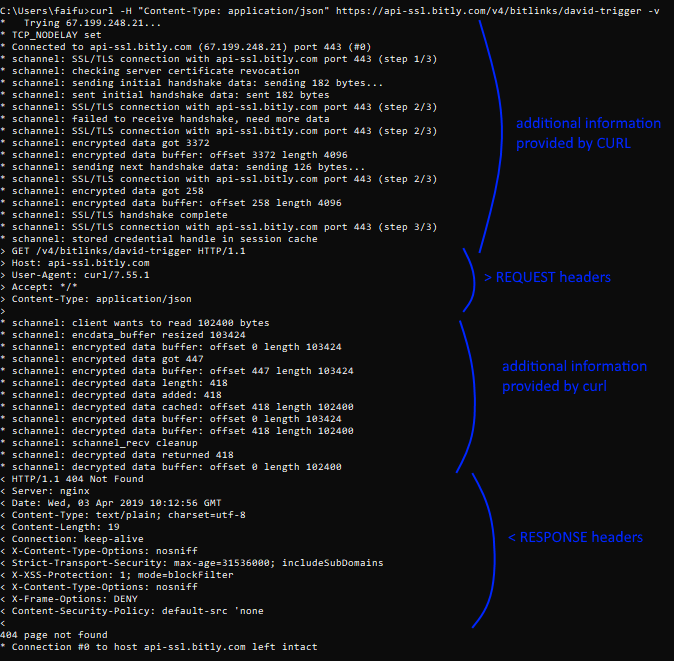
You can send HTTP headers with curl through the -H or --header option.
To view headers you’ve sent, you can use the -v or --verbose option as you send the request, like this:
curl -H "Content-Type: application/json" https://api.github.com -v |
4 Data, Body, Message
The data (sometimes called “body” or “message”) contains information you want to be sent to the server.
This option is only used with POST, PUT, PATCH or DELETE requests.
To send data through cURL, you can use the -d or --data option:
|
Authentication
To perform a basic authentication with cURL, you can use the -u option, followed by your username and password, like this:
|
HTTP Status codes and error messages
When a CURL command returns an error (use --verbose to view full details), the error code can be translated using the HTTP status reference:
MDN’s HTTP Status Reference.
CURL (cURL) https://curl.haxx.se/
CURL is a command line tool and library used to transfer data, and in this blog-context, can be used to access / hit API endpoints.
To test if curl is installed, run the following command:
| curl –version |
Using query parameters
When accessing an endpoint using query parameters, the “?” and “=” need to be escaped in the url.
For example
| curl https://api.something.com/somepath\?query\=queryvalue |
JSON
API responses are often returned in JSON format.
JSON = JavaScript Object Notation
JSON documents can contain non-structured data, in the form of key-value pairs.
|
Example curl commands
curl -u "username:password" https://api.github.com/user/repos -d "{\"name\":\"testrepo12345\"}"
curl -u "username:password" https://api.github.com/repos/{username}}/testrepo12345 DELETE
curl -u "username:password" https://api.github.com/user/repos
|
Thursday, 28 March 2019
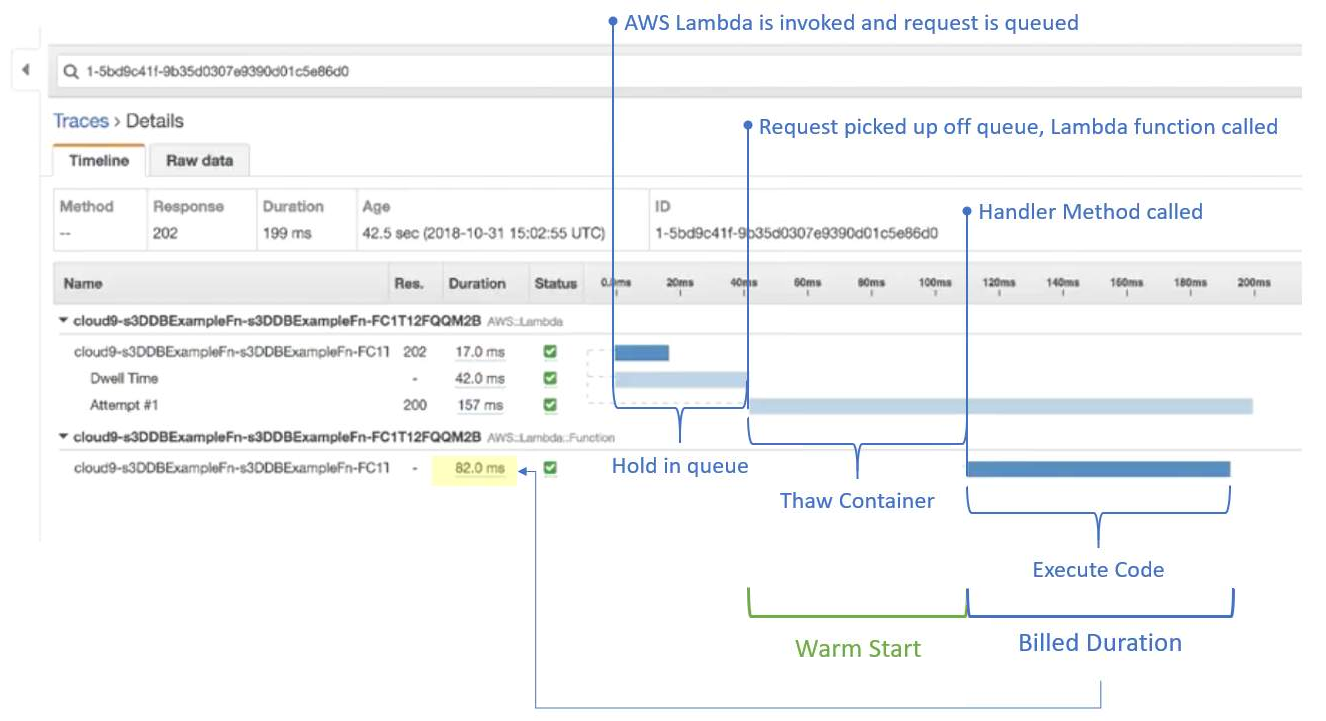
How AWS Lambda works
Below is a diagram (taken from AWS.training) that’s the result of a Lambda cold start, using AWS X-Ray.
In this example, an object is added to an S3 bucket, which asynchronously triggers the Lambda function invocation.
- Asynchronous push events are queued
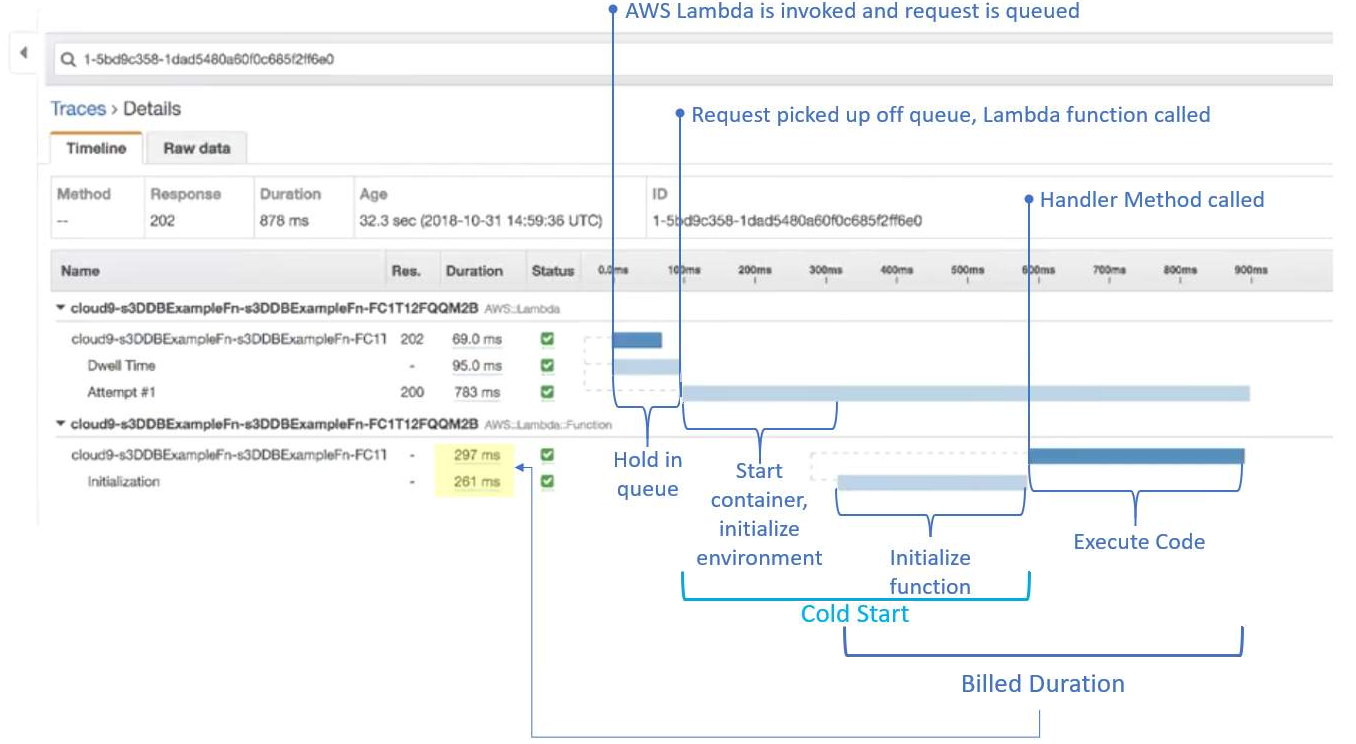
The diagram below is for a Lambda warm start.
Note the shorter duration.
Cold start: 878ms
Warm start: 199ms
The important fact is the lower billed duration of the warm start.
Cold start: 558ms (297 + 261)
Warm start: 82ms
Wednesday, 27 March 2019
Talend TAC Job Conductor Trigger details from database
Below is a simple query to retrieve “Job Conductor – Task – Trigger” details from the database tables associated to Talend Admin Center (TAC).
select |
NOTE
Within the qrtz_cron_triggers table, the cron expression could look similar to
| 0 1,2,3 4,5,6 ? 4 2,3,4,5,6 2020 |
Note that there’s a space to help separate the difference parts of the cron expression
seconds:0 –this is always zero as the cron-scheduler within TALEND doesn’t have the functionality to set to the second.
minutes:1,2,3
hours:4,5,6
days of month:? –this means it’ll run for every day in the month
month:4 –April = 4th month in the year
days of week (1 = Sunday):2,3,4,5,6 –this is for Monday, Tuesday, Wednesday, Thursday, Friday
year:2020
EXECUTION PLAN
When Job Tasks are set up as a sequence, or have inter-relationships (parent child), or setup as some form of hierarchy within the EXECUTION PLAN CONSOLE, then these details can be viewed using the following query:
select |
Wednesday, 20 March 2019
Talend Job Statistics error, Connection refused, connecting to socket
When executing a Talend job via TAC (Talend Administration Center / the Talend Server), the following error message can be returned if the JobServer / Execution service is a remote server.
ie The JobServer or Execution service isn't on the same server as TAC.
[statistics] connecting to socket on port 10226 |
The statistics port 10226 is chosen at random by the server from a range of 10000 to 11000.
The connection is refused if this is blocked by a firewall (or security group in the case of AWS instances).
The details below help correct this.
Changing Statistics port settings
TOS (Talend Open Studio)
Window -> Preferences -> Talend -> Run/Debug and there you can change the stats port range.

TAC
For Talend Administration Center, edit the following file:
TOMCAT_FOLDER/webapps/org.talend.administrator/WEB-INF/classes/configuration.properties
Look for these lines (or add them onto the end of the file):
# The range where find a free port on the Administrator machine, where the job will send the statistics informations during its execution
scheduler.conf.statisticsRangePorts=10000-11000
And then change the scheduler.conf.statisticsRangePorts parameter for the desired range, like this:
scheduler.conf.statisticsRangePorts=10000-10010
The file should look something like this:

Tuesday, 19 March 2019
AWS Webinar: Testing and Deployment Best Practices for AWS Lambda-Based Applications
[This page contains the Q&A from the AWS webinar on “Testing and Deployment Best Practices for AWS Lambda-Based applications.
The details below are useful, but always use this information in combination with your own research.
Answers to the questions were provided by Eric Johnson of AWS during the webinar.
]
AWS SAM: AWS Serverless Application Model
The AWS Serverless Application Model (AWS SAM) is a model to define serverless applications. AWS SAM is natively supported by AWS CloudFormation and defines simplified syntax for expressing serverless resources. The specification currently covers APIs, Lambda functions and Amazon DynamoDB tables.
https://docs.aws.amazon.com/lambda/latest/dg/serverless_app.html
Q: What is your recommendation on creating and maintaining connection pools to RDS / POSTGRES databases that are needed in a Lamba Function?
A: If you are using Aurora Serverless look at the Data API. https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html
Q: Can you use Cloud9 to debug SAM local?
A: Yes, however, C9 also offers a UI for debugging, that is based on SAM local - either work.
Q: I don't really understand the context object of a lambda function. What is it used for?
A: This object provides methods and properties that provide information about the invocation, function, and execution environment.
https://docs.aws.amazon.com/lambda/latest/dg/nodejs-prog-model-context.html
Q: How does debugging work with SAM?
A: You can set breakpoints and have a call stack available. It connects to the debug port provided by SAM Local. https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-using-debugging.html
Q: Is there any way to autogenerate sam template? or need to write it yourself?
A: Using "SAM init" on the SAM cli will create a base template for a project.
Q: How to do canary, an blue/green with serverless?
A: https://aws.amazon.com/blogs/compute/implementing-canary-deployments-of-aws-lambda-functions-with-alias-traffic-shifting/ You can do traffic shifting between your serverless functions. Just what Chris is explaining right now.
Q: If a lambda function is contained on a VPC, being that VPC different per stage… how can we define the VPC to be used for a certain Environment? (if using tags to deploy)
A: You can specify VPC through template parameters.
Q: How to daisy-chain lambdas together?
A: Step-functions allows you to write loosely coupled lambda functions together instead of creating dependency between them. More elegant and less glue code required;
Q: If running a serverless .net core app on a lambda function which exposes numerous endpoints does a cold start relate to the lambda function as a whole or per endpoint?
A: Cold start is specific to a Lambda function and not individual endpoints supported by the same Lambda function. For example: if one endpoint starts the Lambda execution environment, another call to an endpoint on the same lambda function will be warm and ready to go.
Q: Is there anyway to use OpenAPI to generate SAM template?
A: API Gateway resources can use OpenAPI documents to define the endpoints. You can also export your API Gateway to an OpenAPI doc from within the console.
Q: What is the best way to trigger N number of lambda functions at once? Should SQS be used?
A: Lambda functions can be triggered from SQS but it is not guaranteed they will be triggered at the same time. You can also broadcast to multiple Lambda functions via SNS.
Q: Is serverless a good idea to sue for a project where my users start using the app everyday between 8;30 to 9 A.m and shuts down at 5:30 pm?
A: As far as timing, Serverless would work well for this because you will only be charged for the invocations. There will be no resources sitting idle.
Q: is sam also a sub component of the aws cli or will it be?
A: SAM is not a sub-component of the AWS CLI, but DOES depend upon it. For example, SAM package is a wrapper for aws lambda package.
Q: will there be delay to execute the Lamda when user first start using in the morning? considering the cold start ?
A: The first time a Lambda function is invoked there will be a slight cold start delay. The length of this delay is dependant on multiple factors like memory, function size, language, and if it is in a VPC. Outside of a VPC the cold start is often in the milliseconds
Q: Do lambda layers work locally in node js? I've updated aws-cli, sam local, and pip, but this doesn't seem to work locally
A: Yes it does work. You do need the latest version of AWS CI and SAM. Updating AWS CLI requires the latest Python as well for the latest features. If you are on a MAC I have found that using Brew is the best way to install.
Q: Is the AWS SAM CLI suitable for use in automation?
A: Depends on the automation, but I would generally say it is best for development. Automation should be achieved through tools like CodePipeline, CodeBuild, CodeDeploy, etc
Q: Are there some example projects using AWS SAM?
A: The Serverless Application Repository has many examples to look at. https://aws.amazon.com/serverless/serverlessrepo/
Q: Where do the various environment configs live, in their own template files?
A: Configs can live several places. Parameter Store, Build Variables, Template Variables. If using a different account for environments I encourage the use of the parameter store
Q: It seems like when I use layers in sam templates. I need to push from a sam template first to create a new version of the layer. Then manually change the version number in the template to reference the new layer version. Is there a way to reference code that you are zipping up and sending to s3 to become a layer version in the lambda template. Then referencing that same template for zipping into s3 for your layer link?
A: For iterating purposes, if the layer is on the same template you can reference the logical name of the layer. It will grab the latest each time
Monday, 11 March 2019
AWS training links
Below are a short list of links to AWS training material that I’ve found extremely useful.
The 12 Months starts from the account creation
https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc
Please see the FAQ - https://aws.amazon.com/free/free-tier-faqs/
As well as a link to an article discussing tracking free tier usage.
You are also able to leverage Cloudwatch and creating billing alarms
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/tracking-free-tier-usage.html
| Comment | Link |
| AWS Training / Learning library home page. Free registration required. Hundreds of modules to learn about the different AWS services. An incredible resource which is amazingly free. |
https://www.aws.training/ https://aws.amazon.com/events/awsome-day-2019/ |
| AWS Cloud Practitioner Essentials course. A great way to quickly learn the basics of the core services, through watching a series of structure videos with multiple choice questions at the end of each topic to enforce and consolidate your learning. |
https://www.aws.training/learningobject/curriculum?id=27076 |
| Qwiklabs. A a great resource to learn cloud skills. The courses provide sandbox environments to learn new skills. There’s also free courses to learn to help learn some of the basics of the course services. Qwiklabs covers both AWS and GCP. |
https://www.qwiklabs.com/catalog?keywords=&cloud%5B%5D=AWS&format%5B%5D=any&level%5B%5D=any&duration%5B%5D=any&price%5B%5D=free&modality%5B%5D=any&language%5B%5D=any |
| AWS Monthly webinars. These are a great resource to see what’s new, or gleam in depth insight into a particular service.\ These sessions change frequently as AWS services evolve, so also keep popping back to the page to see what’s new. |
https://aws.amazon.com/about-aws/events/monthlywebinarseries/ ARCHIVE https://aws.amazon.com/about-aws/events/monthlywebinarseries/archive/ |
| AWS Documentation. The trusty default go to when you need to reference something within AWS. | https://docs.aws.amazon.com/index.html#lang/en_us |
| AWS Youtube channel | https://www.youtube.com/user/AmazonWebServices |
AWS FREE TIER - when creating a new account -- does the free-tier time/window start as soon as the account is created, or as soon as a particular service is started?
The 12 Months starts from the account creation
https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc
Please see the FAQ - https://aws.amazon.com/free/free-tier-faqs/
As well as a link to an article discussing tracking free tier usage.
You are also able to leverage Cloudwatch and creating billing alarms
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/tracking-free-tier-usage.html
Thursday, 7 March 2019
[NOTES] Building a Highly Efficient Analytics Team
/*
Notes from the PragmaticWorks webinar
https://pragmaticworks.com/Training/Details/Building-a-Highly-Efficient-Analytics-Team
*/
How to build a better analytics team
Analytics teams help differentiate difference businesses.
How businesses use their data to
- optimise business process
- understand what is a “normal benchmark”
- highlight opportunities to improve (based on existing benchmarks)
- highlight new opportunities that wasn’t obvious previously (can’t see the wood for the trees)
How do we define “world class”?
- Attitude
know that there’s always room to learn - Aptitude
grow your skillset to deliver measurable benefit - Adaptability
- Acceleration
How to assess your current team?
- Build a team based on potential, not on current-skill set
Getting from today to world-class
- rate your team on the “4 A’s”
- Clean up low hanging fruit
- Hand off “chores”
- Create capacity for improvement
- Set aggressive 90-day goals
- Get creative with team activities (hack-a-thons etc)
- Create specific plans and targets
- Put your plan into action and socialize results!
Gaining the Necessary Skills
- What skills are needed?
- Data Cleansing
- Data Modelling
- Data Analysis eXpression
- Data Visualization Best Practice
Good story telling, guiding the user through the main themes/conclusions that the data presents - Power BI Administration
- Data Governance
- How do you gain these skills?
- Free webinars
- Blogs
- Books
- YouTube
- On-Site Training
- Web-based On-Demand Learning
Pluralsight, Udemy - Pushing your team
- Set goals
- By the end of the month, you should know how to…
- By the end of the Quarter, you should know how to implement …
- Find out what motivates the team
- Competition between co-workers
- Buy lunch for your team when they reach a goal
- Define Learning Paths
- What things you want your team to know, and in what order
- Other considerations
- Specialist vs Jack-of-all-Trades
- Find ways to jump start your teams experience early (Hack-a-thons)
- Value of Certifications
Be prepared why certifications are valuable, and what was learnt, and how that matters
Wednesday, 16 January 2019
Talend Open Studio – Configure Statistics and Log Capture
Within TOS (Talend Open Studio) – the project settings can be configured to allow component-level statistics and log capture.
This information can be directed to database tables for later review.
The tables are
These tables can be created by watching: https://www.youtube.com/watch?v=31EY-VhjjoA
Or by following http://diethardsteiner.blogspot.com/2012/02/talend-setting-up-database-logging-for.html
Below are the steps to configure a TOS project so that the components log stats during execution.
(it’s fairly intuitive)
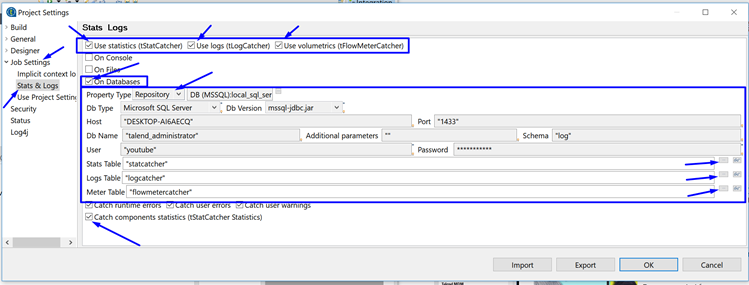
2) In the project settings window, navigate to Job Settings>Stats & Logs
3) Tick the boxes in the upper right for
5) Finally click on the ellipse’s to help choose the correct logging table within the database.
6) Optionally, also tick the Catch components statistics (tStatCatcher Statistics).
This information can be directed to database tables for later review.
The tables are
- StatCatcher
- LogCatcher
- FlowMeterCatcher
These tables can be created by watching: https://www.youtube.com/watch?v=31EY-VhjjoA
Or by following http://diethardsteiner.blogspot.com/2012/02/talend-setting-up-database-logging-for.html
Below are the steps to configure a TOS project so that the components log stats during execution.
(it’s fairly intuitive)
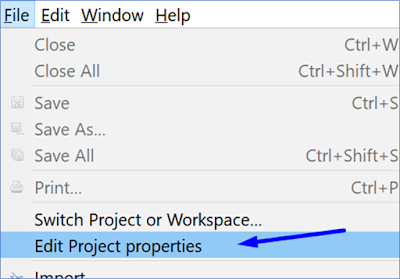
Project Properties
1) Open a project, and click File>Edit Project properties
Project Settings
2) In the project settings window, navigate to Job Settings>Stats & Logs
3) Tick the boxes in the upper right for
- Use statistics (tStatCatcher)
- Use logs (tLogCatcher)
- Use volumetrics (tFlowMeterCatcher)
5) Finally click on the ellipse’s to help choose the correct logging table within the database.
6) Optionally, also tick the Catch components statistics (tStatCatcher Statistics).
Subscribe to:
Posts (Atom)